



With our Strategic Planning solution, you remove gut feel and make calculated decisions for multiple long term strategies. Know exactly which future staffing issues will arise and the total labor costs per region and location.


Get the right people at the right time and place to decrease your overstaffing up to 50% and understaffing up to 40%

Fully adhere to labor laws and business rules and follow as many employee preferences as possible

Move from spreadsheets to our solutions and power up your software to give you better schedules and hours back
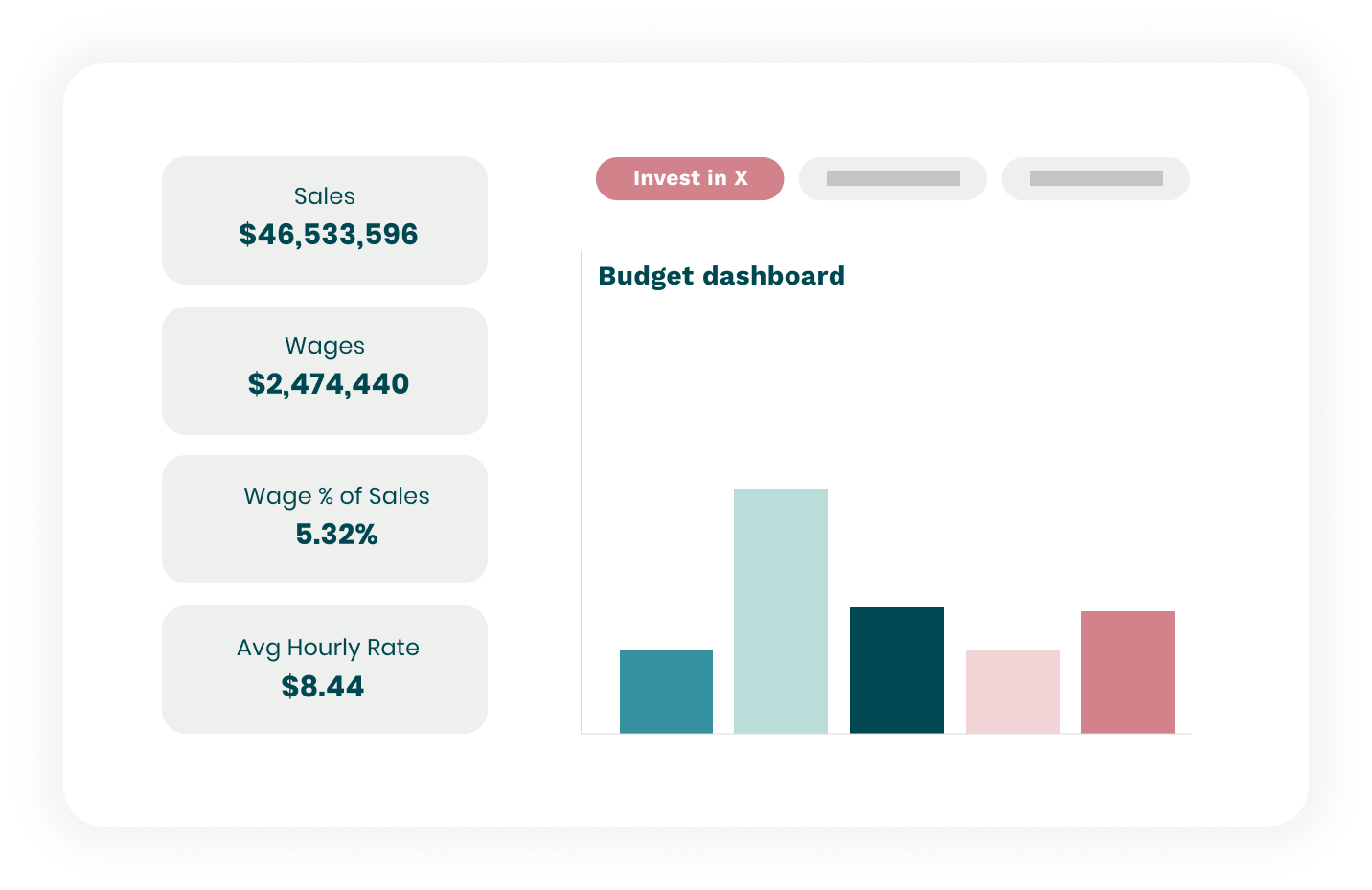
With our Strategic Planning solution, you remove gut feel and make calculated decisions for multiple long term strategies. Know exactly which future staffing issues will arise and the total labor costs per region and location.
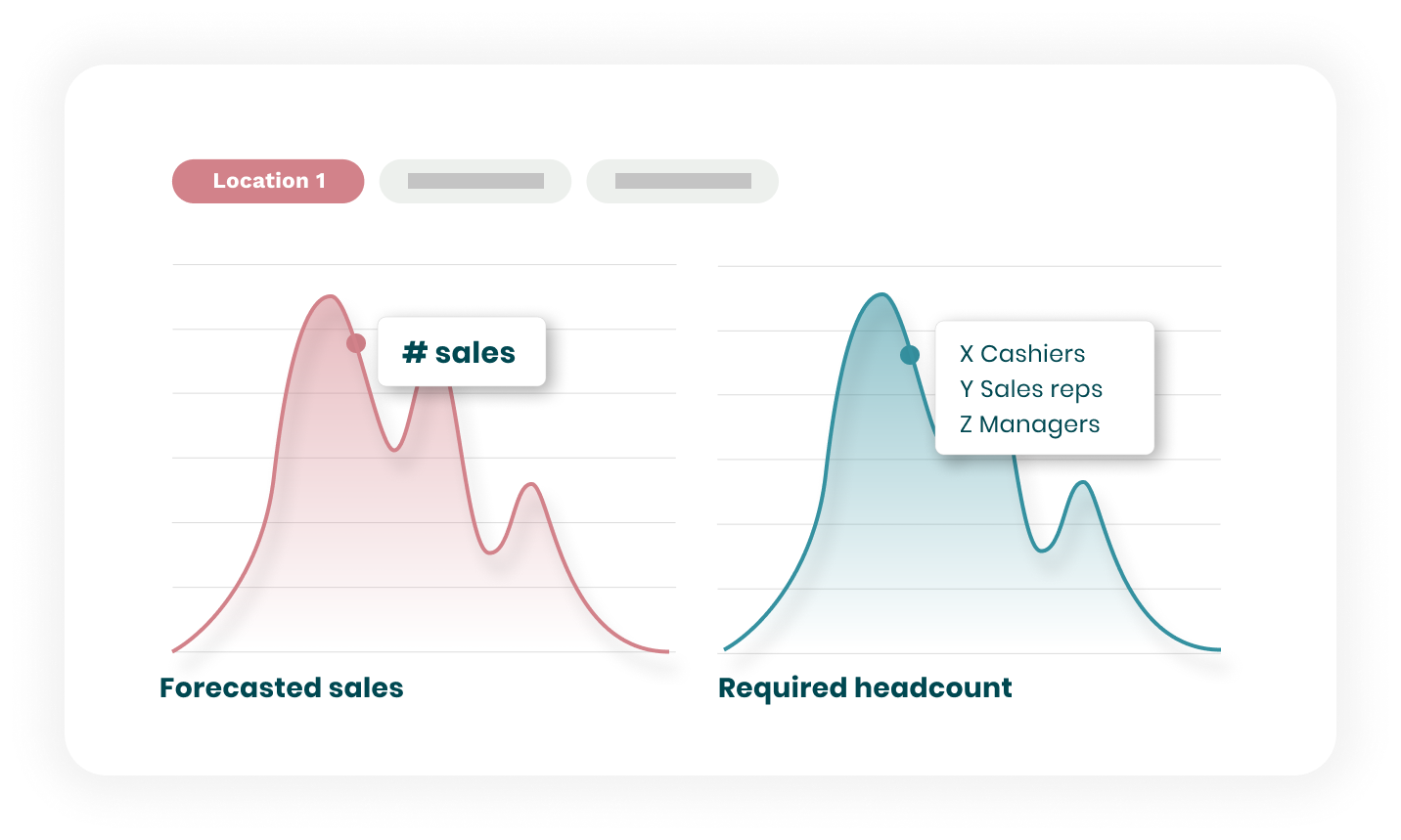
With our Demand Forecasting solution, you can create the most accurate future outlook yet. The perfect base to staff against and to create schedules that follow. 
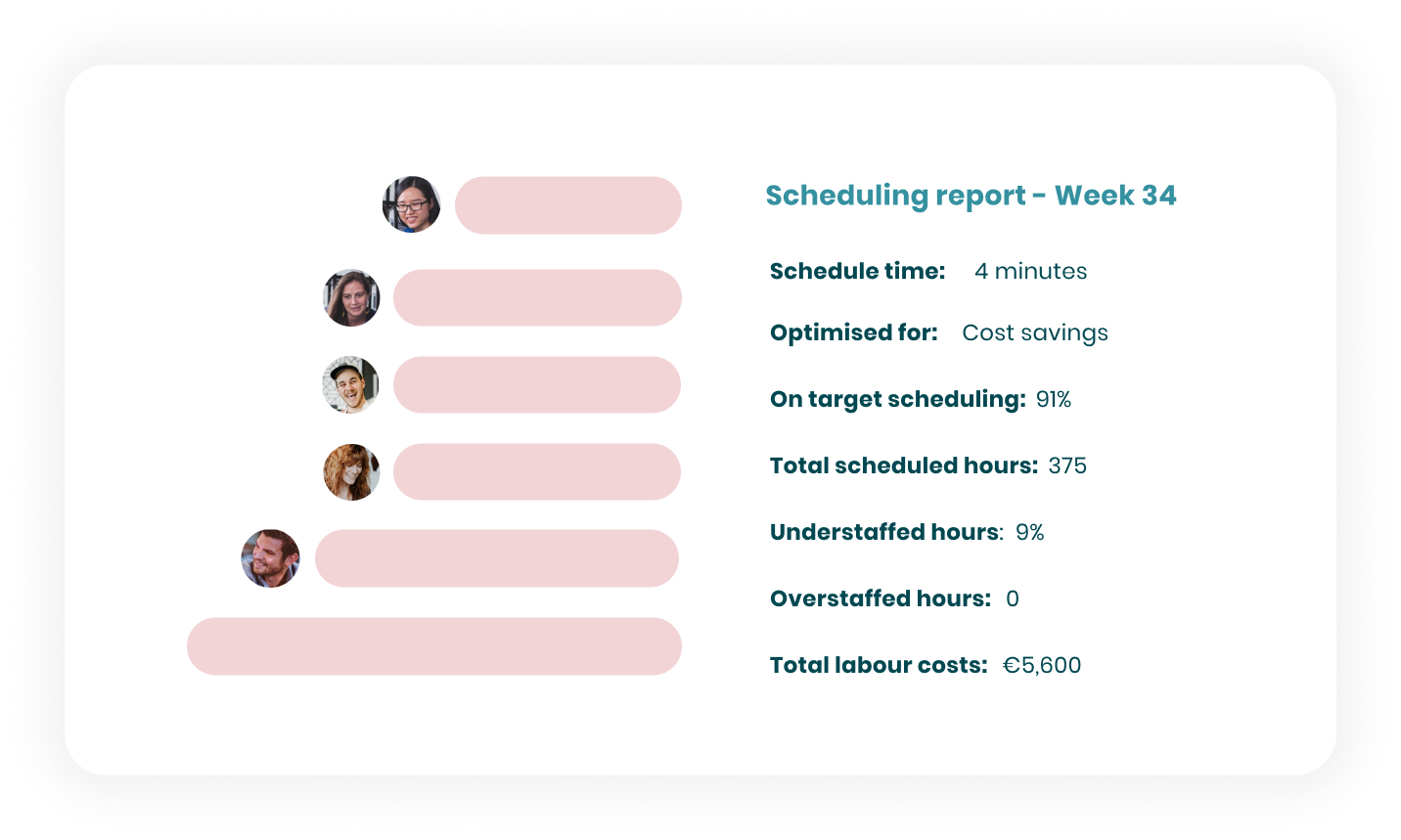
With our Labor Optimization solution, you only have to choose your business objectives, our technology does the rest. Make automated schedules in minutes and minimize manual changes mid-operations. Unintentional over and understaffing are officially a thing of the past.

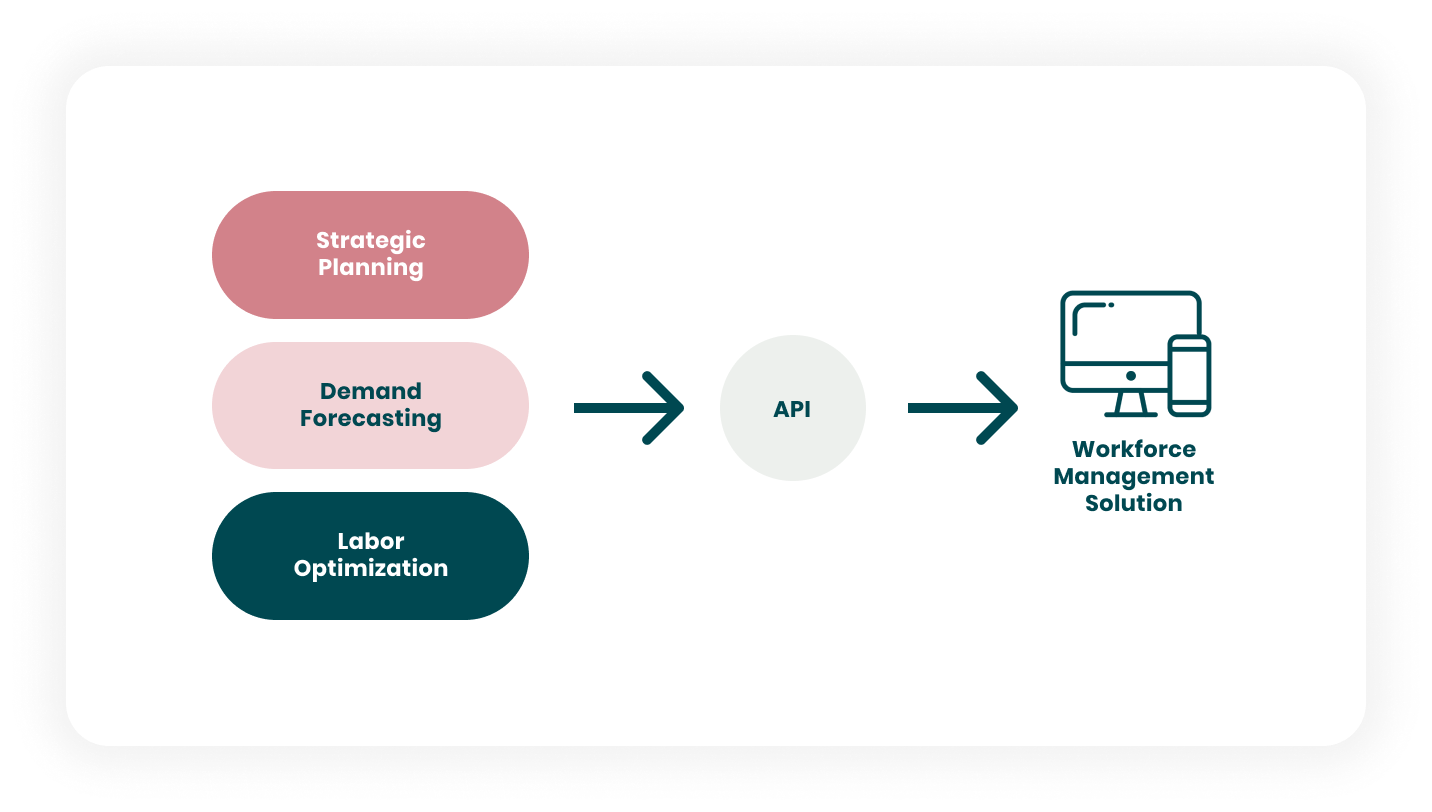
Empower your Workforce Management system with our AI Optimization solutions and take your workforce management to new heights. Connect easily to the Quinyx platform API to add AI to your software.

Quinyx is helping us to ensure that we have the right people at the right times in the right places in every one of our centers.Jason BallChief Operations officer | G8 Education
Enter your details below and we’ll be in touch to book in a free, no-obligation demo with you.
Is this a support inquiry? Please use our Help Center ›